
We introduce HouseTour, a method for spatially-aware 3D camera trajectory and natural language summary generation from a collection of images depicting an existing 3D space. Unlike existing vision-language models (VLMs), which struggle with geometric reasoning, our approach generates smooth video trajectories via a diffusion process constrained by known camera poses and integrates this information into the VLM for 3D-grounded descriptions. We synthesize the final video using 3D Gaussian splatting to render novel views along the trajectory. To support this task, we present the HouseTour dataset, which includes over 1,200 house-tour videos with camera poses, 3D reconstructions, and real estate descriptions. Experiments demonstrate that incorporating 3D camera trajectories into the text generation process improves performance over methods handling each task independently. We evaluate both individual and end-to-end performance, introducing a new joint metric. Our work enables automated, professional-quality video creation for real estate and touristic applications without requiring specialized expertise or equipment.
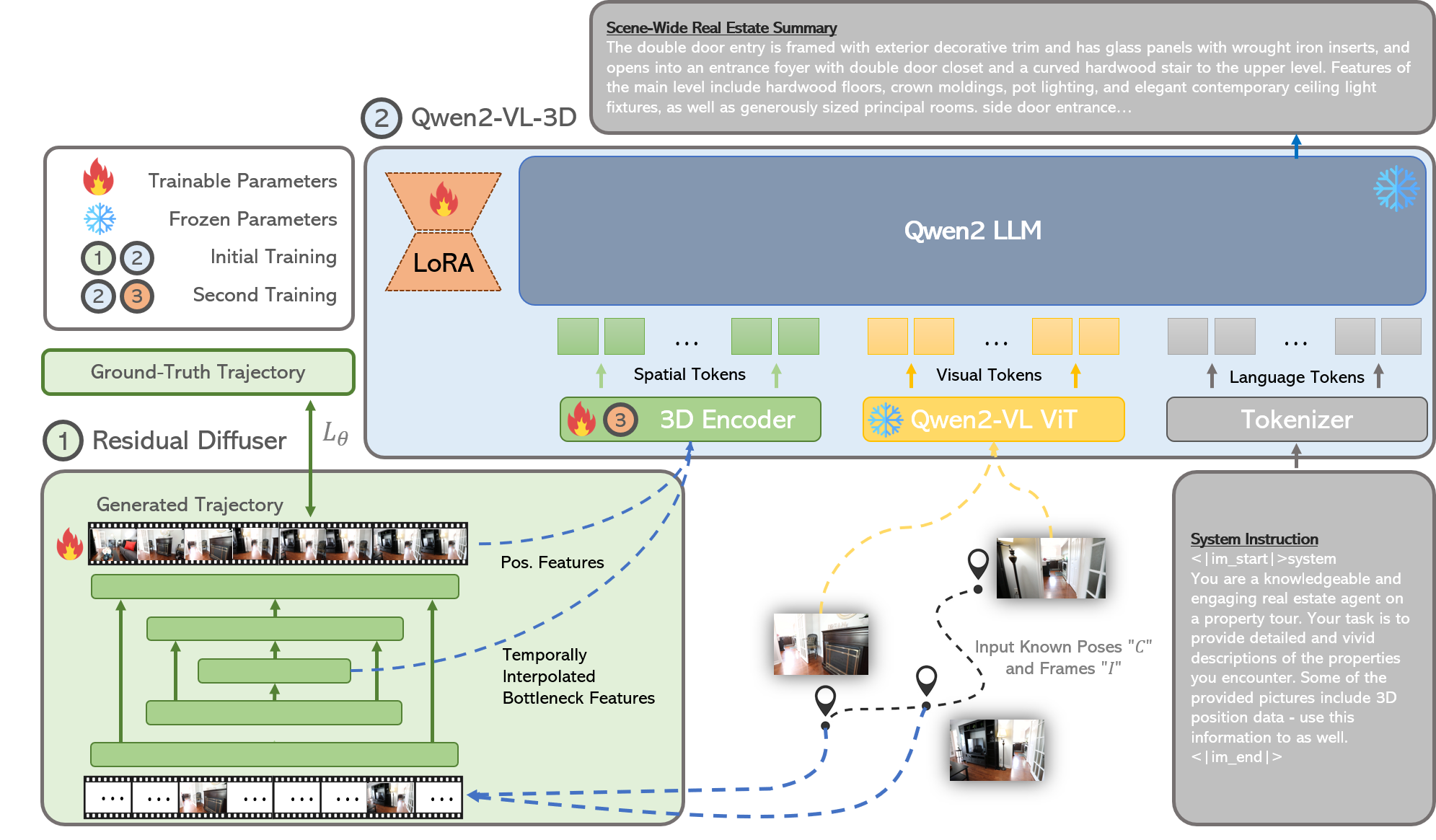
HouseTour generates 3D camera trajectories and natural language summaries from RGB images with known poses of real estate spaces. Our approach consists of two primary modules: Residual Diffuser and Qwen2-VL-3D.
Built upon "Diffuser", the Residual Diffuser is a diffusion model that generates 3D camera trajectories, which mirror human-like movement in real estate tours. It utilizes a masked diffusion process to create smooth video trajectories, constrained by known camera poses, and integrates this information into Qwen2-VL-3D for 3D-grounded descriptions. This residual-based approach enables the model to focus on learning the nuanced deviations from the spline baseline that characterize realistic human camera movement, rather than memorizing absolute trajectories for each unique scene. By predicting only the residuals, the model generalizes better across diverse environments and adapts to the dynamic nature of real estate layouts. The combination of spline interpolation and learned residuals ensures smooth, plausible trajectories that respect both geometric constraints and human-like navigation patterns. This formulation also simplifies the conditioning process, as the model only needs to enforce zero residuals at known camera poses, allowing for efficient and deterministic integration of sparse observations. Overall, our Residual Diffuser provides a flexible and robust solution for trajectory planning in complex, variable 3D spaces.
The Qwen2-VL-3D module is a vision-language model that generates natural language summaries of the 3D space, leveraging the generated camera trajectory. This integration of spatial features enables Qwen2-VL-3D to attend not only to the visual content of each frame but also to its precise location and movement within the property. By encoding both the pose and the learned trajectory features, the model can incorporate information about the spatial relationships between rooms, the flow of movement, and the overall layout, resulting in more contextually accurate and informative summaries. During inference, the model leverages these spatial tokens to generate descriptions that reference architectural highlights, closely emulating the narrative style of professional house tours. This approach ensures that the generated summaries are grounded in both the visual and spatial realities of the property, providing users with coherent, detailed, and spatially-aware walkthroughs.

The HouseTour Dataset contains over 1,600 real-estate tour videos with aligned camera poses, 3D reconstructions, and professionally written property descriptions, enabling research in multi-modal scene understanding. The data is procured from professional real-estate agencies and we acquired rights for sharing and using. Our dataset comprises:

Here we present a qualitative example of our summary generation, illustrating how the produced text corresponds to specific spatial elements and sampled images from the environment.
This work was supported by an ETH Zurich Career Seed Award.
@inproceedings{çelen2025housetour,
title = {HouseTour: A Virtual Real Estate A(I)gent},
author = {Çelen, Ata and Pollefeys, Marc and Baráth, Dániel Béla and Armeni, Iro},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
year = {2025}
}